An Issue of Growth and Complexity
Large enterprises continue to struggle with growing amounts of data and complexity across their transactional and analytical platforms. Although the continued expansion of data is not inherently a problem, it compounds data management challenges, especially for enterprises that strive to be data-driven. Data growth is driven by business activity, new functional requirements (e.g., analytics, telemetry), and inefficient data lifecycle management. Complexity, on the other hand, often results from inadequate data ownership and stewardship: In the absence of individual accountability, sub-optimal decisions and workarounds lead to elevated consumption of resources. Frequently, this complexity is caused by a failure to establish a set of best operational practices, including- Transformable data architecture, system reliability as well as failure resiliency, data quality standards, guarantees of SSOT, and real-time capabilities. Common pitfalls include the failure to establish clear transport layers, circular source referencing, excessive customization, and insufficient data governance.
Over time, inefficient data architecture and sub-par operational practices become ingrained, which renders undoing them all the more challenging. Under the traditional centralized data architecture model, as companies grow, communication between different generations of legacy data warehouses, ERP systems, and consuming applications becomes disparate. Specifically, the centralized model design, unable to keep up and starts fragmenting, which results in fragility and failures that render maintenance difficult and costly. Notably, this centralized model stands in stark contrast to younger start-ups, which were able to avoid centralization pitfalls by adhering to modern architecture patterns from inception. In the absence of good data hygiene, as the size and intricacy of data assets continues to grow, scaling operations and building new features becomes ever more challenging. Inefficient data practices keep CIOs from achieving their strategic goals, as they are forced to allocate ever larger portions of their IT budgets to maintenance, rather than investing in next-gen tech and innovation.
“ …leveraging cloud-based technologies
like Snowflake alone does not suffice…”
To prepare for the demands of the next decade, technology leaders must address the complexity within their existing data environments, and fundamentally re-evaluate how to best plan for and architect next-generation data platforms. This paper offers a perspective on how to approach remediating complexity within legacy data environments and lays the groundwork for building a domain-centric data architecture framework. This effort encompasses the creation of standards and governance, data architecture and underlying design principles, and their integration with novel cloud-based solutions and distributed databases. However, we also show that leveraging cloud-based technologies like Snowflake alone does not suffice to address the fundamental data issue at hand: CIOs must acknowledge that adhering to the status quo will result in a repetition of past failures. In what follows, we present a perspective on an ideal architectural target-state design and outline concrete next steps for CIOs to get there.
How We Got Here
The last ten years have seen exponential growth in the volume and variety of data that large enterprises process and store, and this rapid expansion has introduced complexity. Indeed, the research firm IDC reports that the ratio of unique data (created and captured) to replicated data is roughly 1:9, providing a glimpse into the lack of efficiency.1 Nonetheless, about 80 percent of data remains ungoverned, as existing policies are often not ubiquitously enforced.2 And data do need to be governed for the following reasons:
1.Proliferation of data replicas with ambiguous origination
2. Absence of data-as-a-service paradigm
3. Inconsistent data due to multiple sources of truth
4. Regulatory compliance requirements, such as GDPR
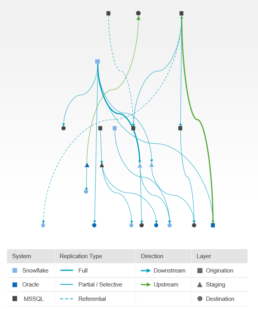
For remediation, companies should consider their entire data lifecycle: where and how data is created, stored, cataloged, transformed, distributed, archived, and purged. Conducting a comprehensive “as-is” mapping of critical data entities and flows (Exhibit 1) helps to identify the most pressing hotspots. In parallel, companies should start planning for an ever-more demanding future when it comes to data processing capabilities. This planning should not fall back on over-centralized models, and should instead consider proven, though not widely spread architectural approaches like domain-centric design.
Exhibit 1. Sample Data Flow Visualization
(i.e., data entities and feeds from Fortune 500 firm)
The Cloud is Not Enough
Global enterprises have long started to embrace public cloud offerings to augment their data capabilities. In July 2020, HSBC announced its pivot to the public cloud and a partnership with Amazon Web Services (AWS). In 2019, Amazon’s consumer business decommissioned its last Oracle database.3 Snowflake is an example of a SaaS data platform currently being adopted across the industry. Forrester Consulting estimates that over a three-year period, Snowflake has saved companies $21M per year in storage, compute, and labor.4
Migrations to providers like AWS and Snowflake highlight the increasing popularity of public cloud for data operations, as these database solutions reduce the internal IT efforts required, as well as the hardware costs and lead times for new products. However, even with mature solutions available, large on-prem databases and private cloud deployments remain common, which is attributable to perceived increase in control, difficulty in migrating away from legacy, and the burden of investments that were made to build them in the first place.
At this moment, most enterprises have come a long way and are building their third-generation data platforms. The first-generation platforms consisted of proprietary ERP systems (e.g., Oracle), enterprise data warehouses, and business intelligence platforms. High complexity, unmaintained batch jobs, excessive customization, and complex reports contributed to the amount of data integrated into proprietary systems, and to increasingly customized ERP systems, thus resulting in an even steeper increase in system resource usage.
The second-generation of data platforms addressed some of these limitations by introducing big data ecosystems with data lakes at their core, often still relying on batch processing by default. The latest generation aims at improving upon the second generation by enabling real-time processing and embracing XaaS solutions (e.g., Snowflake), data pipeline management (e.g., Pachyderm), and ML (e.g., C3.ai). This ability to process data in real-time enables near-real-time analytical capabilities and reduces the cost of running big data infrastructures. However, key limitations related to a centralized design paradigm remain: These monolithic models can work for organizations with limited complexity and use cases but are unsuitable for enterprises with rich domains, diverse data sources, or multiple consumers.
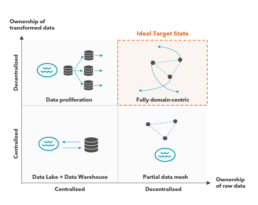
To build a robust future-proof data architecture framework, companies must first have a comprehensive view of their current “as-is” (data entities and feeds). A thorough assessment of the current state will not only uncover the major gaps, vulnerabilities, and redundancies, but will also identify the most expensive deviations from proper data architecture standards, thereby helping to prioritize the remediation steps. As companies work toward efficient data frameworks, arguably the most significant steps taken have been in the embrace of domain-centric paradigms and cloud-native design patterns. A holistic assessment of data assets and feeds can help drive continuous improvement and is vital for uncovering the systemic data architecture-related challenges that increase system costs. The subsequent section will outline what CIOs can expect from a domain-centric target-state as well as the steps required to get there.
Defining The Target State
The movement toward democratization of data at scale is not novel. Companies have long aimed to build scalable structures to support business insights and automated intelligent decision-making from disparate data sources. However, traditional data platforms based on data warehouse-like architecture are subject to single points of failure (SPOF) and will face challenges as they scale up. Notably, such an approach will help companies move toward an embrace of self-service as well as the provision of data as a service. The motivations for undertaking this effort are clear:
1. Enable real-time data use for customer-centric experiences
2. Reduce operational costs through data-driven optimization
3. Empower decision making via analytics and business intelligence
Organizations have been investing heavily in data warehouse systems and business intelligence platforms. However, despite increasing efforts and investment dollars, results have been middling. Enterprises face considerable complexity when they embark on a journey to transform their data architecture, as shifting from decades-old legacy systems and the culture that accompanies them is a daunting challenge, both organizationally and technologically. Building distributed architecture at scale requires enterprises to relinquish their biases toward traditional data platform architecture, and to move away from an ecosystem of centralized and monolithic repositories toward a fully-distributed data architecture paradigm.
Exhibit 2. Data Integration Patterns Used Today
The remainder of this paper presents the ideal data architecture (“What ‘good’ looks like”), a three-phase transformation approach (“planning the future”), and tangible steps that large enterprises can take toward remediation, with immediate benefits (“getting started”).
Embracing Domain Centricity
The future of enterprise data platform architecture will see the integration of a distributed, domain-driven data architecture, self-serve infrastructure platform design, and product-centric delivery thinking. This shift requires three distinct steps:
1.Breaking the monolith: distributed, domain-driven architecture
To drive decentralization, domains must publish and share their datasets in a manner that is easily consumed, rather than moving data from domains into centrally-managed data repositories or platforms. The infrastructure setup, location of datasets, and manner of data flow, are all technical implementations. Storage could certainly be reliant on cloud-based infrastructure, but the ownership and management of the data products remains with the originating domain team.The domain-centric design does not mandate the complete eradication of duplicate data. As data is transformed and augmented, different domains may serve different purpose-built data sets. However, this approach requires a mindset shift from thinking in terms of a push-and-ingest model via ETLs and event streams, toward an offer-and-consume model that spans across individual domains.
2. Product-centric thinking
The shift toward distributing data asset ownership and data pipeline implementation responsibility to individual business domains raises important concerns with regards to the accessibility, usability, and harmonization of data assets. Following a product-centric and ownership-driven approach for managing data assets is paramount. Over the past ten years, business divisions have embraced the concept of product-centric thinking when designing the capabilities that they offer to the rest of their organization. Going forward, domain teams will expose and provide these capabilities as APIs to other developers. As part of this process, the implementing teams should aim to best possible developer experience for the APIs of their domains, including accessible and clear documentation, sandbox environments, and KPIs to continuously track their service delivery quality and adoption.To ensure the success of distributed data platforms, data teams within each domain must apply rigorous product-centric thinking to their data offerings. A critical quality of any technical product (e.g., data assets offered by each domain) is the ability to serve its consumers needs; in this instance, the customers are data consuming platforms, data engineers, machine-learning engineers, and data scientists.To provide a superior user experience, data products should embrace the following qualities:
a) Discoverability: data is discoverable via a central data catalog
b) Reliability: owners provide acceptable SLOs for data offerings
c) Interoperability: products follow standards and harmonization
d) Controllability: centrally-defined domain access-control policies
e) Cross-functionality: teams include owners and data engineers
In summary, data assets must be treated as a fundamental component of any application ecosystem. As such, data engineers and developers must become knowledgeable of and experience with the creation of data products. Similarly, infrastructure engineers must become acquainted and comfortable with managing data infrastructure.
A prevalent lack of internal data engineering skills has led to centralized data engineering teams that are siloed and hyper-specialized. To counter this trend, firms must strive to provide skill building and career development opportunities for generalists, promoting their transformation into data engineers.
3.Self serve platform design
Among the main concerns about distributing data ownership to domains are the duplicated efforts and skills required to operate the data pipeline’s technology stack and infrastructure within each domain. However, building common infrastructure as a platform is a well understood and previously solved problem, though the tooling and techniques are not as mature in the data ecosystem. Running a shared data infrastructure platform mitigates the need to duplicate efforts of setting up multiple data pipelines, storage capabilities, and data streaming infrastructure.A separate infrastructure group should manage the provision of the technologies used by each domain to host, capture, process, store, and publish the individual data products.Using cloud data infrastructure services like Snowflake reduces the internal management and operational effort required to provide data infrastructure services; however, this approach also limits the ability to adhere to high-level abstraction principles that should be put in place in the context of the business. Regardless of the individual cloud service provider, a broad and continuously growing set of data infrastructure services is available for consumption by the internal data infrastructure teams.
Making The Change : A Three- Phased Roll-Out
The implementation of a fully domain-centric framework can seem daunting. Given the need for an exhaustive design, which requires considerable analysis time and human capital, it is useful to divide the rollout into three phases: Short-term remediation, mid-term façade construction, and long-term evolution to the target state (Exhibit 3).
1.Remediation
Before making any structural changes, an “as-is” mapping should be undertaken to capture data and feeds for critical business processes (e.g., distribution, finance, procure-to-pay). The current state of data flows can then be mapped to business processes and subsequently analyzed to identify critical operational issues (e.g., circular references, dependencies, feed types). This process paints a picture of how data interacts internally and externally; laying out this view is an important first step toward preparing the organization for full domain centricity.
A clearly articulated and exhaustive data governance framework is the foundation of an ideal target state, but such a framework is more a means to an end than the goal itself. An ideal target state from a data governance perspective is one that has:
a) Decommissioned all non-essential data feeds and data objects
b) Migrated data from on-prem to public, cloud-native enabled DBs
c) Upheld single source of truth (SSOT) for all internal data feeds
d) Leveraged management tools for data cataloging (e.g., Alation)
Exhibit 3. Transformation Toward Domain Centricity

2.Façade scaling
In the medium-term, the move toward domain centricity can begin by way of incremental encapsulation. New consumers or producers that come with, for instance, the addition of new applications, provide an opportunity to scale-up façades: Rather than processing data through traditional, less sophisticated means like table-to-table replicas, organizations may pivot to APIs to promote efficient and sustainable data processing. Pursuant to a system change, a façade (i.e., an API endpoint) must, at a minimum, be introduced, even if data persistence cannot be abstracted from the main producer or consumer (e.g., a custom legacy design for the main application that ingests the data). For API tools, two central paths may be pursued: Using tools like MuleSoft to build APIs (i.e., engineering / development), or tools like Mashery for managing APIs (e.g., logging, monitoring, alerts, IAM).
3.Target state actualizing
Finally, in the long-term journey toward the target state, using next-generation data architecture patterns, principles, and technologies can foster implementation of transparent data services that do not rely on specific databases themselves. In the same vein, transparent interactions between simple primary and complex composite entities can be facilitated with microservice-based architecture. In short, domain-centric data models reach full maturity as they become interoperable and secure.
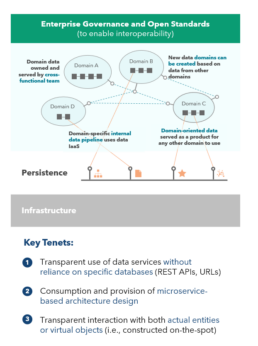
The Shift Toward Domain Centricity
Most of today’s data platforms are monolithic, highly-coupled, and operated in silos. In this whitepaper, we have introduced the building components of a ubiquitous, distributed, and domain-centric data architecture, with a focus on data products that are geared toward domains. These products are operated by integrated, cross-functional teams, comprising of data engineers and product owners, and use a common infrastructure platform. This platform facilitates the hosting, preparation, and publishing of data assets. A domain-centric approach requires a distributed architecture and data model that are based on open standards and governance to ensure harmonized operations and self-service (Exhibit 4).
In the proposed model, database technologies will be purpose specific and available to domains in a service-like fashion to address common data use cases, like highly structured, relational databases (e.g., PostgreSQL), semi-structured setups (e.g., MongoDB), and specialized data structures, such as HyperLogLog (e.g., Redis).
Just as data services are abstracted away from users, infrastructure is abstracted from data services. Interoperability is guaranteed via open-source standards enabling faster technology adoption. This approach paves the way for new technology, like the enablement of high-performance compute for analytical (e.g., Nvidia Ampere), and non-volatile storage for transactional workloads (e.g., Intel Optane).
Exhibit 4. Domain-Centric Architecture
In Closing...
Developing a clearly-defined vision for a domain-centric data architecture is necessary for enterprises to minimize complexity. However, while the technology is ready, enterprise-scale adoption of domain-centric design has yet to materialize. A primary shift will require focus on domain-driven data products, as the underlying infrastructure and tooling are merely implementation details. The same applies for any central data platforms facilitating reporting and visualization tasks: They are simply another data consumer.
Empowering visionary data architects that are comfortable departing from current-state centralized, monolithic design principles will therefore also be key. The paradigm shift described here will also require a new set of governing tenets focused on
1.Serving rather than ingesting data
2. Discovering and consuming vs. extracting and replicating
3. Publishing and subscribing to events via enterprise message bus
4. Creating a uniform/homogenous and distributed ecosystem vs. multiple centralized platforms
The need for better data architecture is real and pressing, and the tools and technology are ready. It is up to technology leaders to acknowledge that maintaining the status will result in a repetition of past failures, despite using cloud-based tooling and platforms.
__________________________________________________________________________________________________________
- “IDC’s Global DataSphere Forecast Shows Continued Steady Growth in the Creation and Consumption of Data.” IDC, May 2020.
- “Information Governance Strategies For Lifecycle Control: Structured Data Archiving.” Iron Mountain.
- Ghosh, Paramita (Guha). “Data Governance in the Cloud.” DATAVERSITY, 31 Aug. 2018.
- “The Total Economic Impact™ of Snowflake Data-Warehouse-as-a-Service.” A Forrester Total Economic Impact, June 2018
Read More

Rethinking the Future of your Business
The economic climate is becoming increasingly uncertain with cautionary signals of recession, along with inflationary pressure, fluctuating currencies, and uncontrollable impact of geopolitical events. Firms need to proactively take this opportunity to refocus their future investments on high value, high potential business lines.

Technology and Healthcare
Data production in healthcare occurs in different volumes, velocities, and formats by multiple sources – EHR, diagnostic, imaging, claims, billing, medical devices to name a few.

Enterprise Cyber Resilience in a Hybrid World
Cybersecurity incidents are also not only a threat to corporations’ internal operations and bottom line; customer personally identifiable information and financial data is also at serious risk of exposure and misuse, in turn impacting customer perception and long-term brand loyalty.

Finding Growth in US Insurance
In the current environment, streamlining the bottom line is no longer enough for US insurers. To find the next wave of growth, insurers must rethink lead generation, agent interactions, and the way they service customers.

Data-Driven Post-Merger Integration
A common misconception is that revenue synergies are illusive or “icing on the cake”, primarily because they are more challenging to quantify.

Monetizing Data Analytics
For several years, it has been said that “data is the new oil” and arguably, the most valuable strategic asset for a business. Whilst getting value out of data might be less straight-forward, it is true that data needs to be refined to make it valuable.

Platformization of Health Tech
Healthcare organizations must harness the momentum of platforms, embracing unified solutions that may still be evolving. Benefits extend beyond cost savings, paving the way for establishing long-term relationships with vendors. Simultaneously

Are Your Vendor Risks Under Control?
Investing in vendor risk management today can secure a future brimming with cost-effective, secure, successful and trust-worthy partnerships.

(AI)ntelligent Procurement
In a competitive business environment, high-performing CPOs are 18x more likely to fully deploy AI/cognitive capabilities. This typically leads to 92% faster demand forecasting, on average 350 man-hours are saved through automation, and there is a potential for 24/7 operations

Realizing Your Workforce Strategy
Organizations are now recognizing the limitations in their workforce programs, so are making a concerted effort to develop a contingent workforce strategy, consolidate their master vendors/staffing agencies, and extract maximum benefits from the program.

Gaming and Financial Services
As younger generations start to play for competition and skill development, there is a rise in payment flows, volumes, and subsequent opportunities arising out of the same. Financial institutions are not only presented with the opportunity to monetize on gamers but also target younger Gen Z and Millennial consumers to upsell and cross-sell their existing products.

Maximizing Value from Value Added Resellers
The payments industry has been experiencing explosive growth across Latin America over the past few years: cash usage has decreased ~20% as consumers pivoted towards payment products that are well integrated into the financial ecosystem.

Latent Growth in LatAm Credit Cards
The payments industry has been experiencing explosive growth across Latin America over the past few years: cash usage has decreased ~20% as consumers pivoted towards payment products that are well integrated into the financial ecosystem.

Navigating the Buy Now Pay Later Era
The rising aspirations of consumers combined with the limited access to, and opaque nature of traditional financing solutions, has given rise to innovative products for underserved segments. BNPL is one such solution that offers short-term financing to users with the ability to pay in definite installments with low to no interest rates.

Modernizing B2B Client Delivery
Getting the Basics Right

Winning in Mature Markets
Competition is an important facet of business world, and the process of seeking growth is a continuous one. One should never stop trying to win new customers or retain existing ones. After all, competitors are always trying to win your customers over, especially in mature markets.

Putting Customers At The Core of Your Business
Digital Transformation is about developing new capabilities and leveraging new channels to design and deliver a better client experience.

Realizing the Reality of Real Time Payments
Real time payment (RTP) transactions are likely to exceed 300B by 2023, growing at 40% per year worldwide. Financial Institutions need to quickly find their own space in this ecosystem. They must redefine their value proposition and rethink their business models around this phenomenon.

Embracing Open Banking
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

Ensuring Loyalty of your Prized Clients
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

The Tale of Two Countries – Insurance
The pandemic has created unprecedented challenges for the insurance industry. Experiences of the world’s biggest economies (U.S. & China) offer valuable lessons as to where the industry can improve and change in order to better handle similar events in future and build sustainable risk management systems.

The Cloud-Native Paradigm
Strategic direction is evolving rapidly during COVID-19. Businesses are struggling with ways to respond to the pandemic and have numerous challenges facing them including potentially significant revenue shifts, interaction changes and resource limitations.
Fortunately, organizations can analyze readily available data by using both business and data intelligence to better serve their customers.

Business Analytics in Pandemic Times
Strategic direction is evolving rapidly during COVID-19. Businesses are struggling with ways to respond to the pandemic and have numerous challenges facing them including potentially significant revenue shifts, interaction changes and resource limitations.
Fortunately, organizations can analyze readily available data by using both business and data intelligence to better serve their customers.

Path to Innovation
Innovation has been in vogue for over a decade but the need to be innovative has never been felt as strongly as today. As businesses are learning to thrive under the lasting effects of the pandemic, they need to reinvent products, services and customer experiences to satiate emerging patterns of demand. To truly capitalize on the opportunity, business leaders need to look beyond internal capabilities and embrace a networked model of innovation to drive positive impact.

Reimagining Marketing
The COVID-19 pandemic has re-shaped the landscape for marketers. They are not only forced to cut budgets to save costs, but also face the challenge of keeping up with new emerging customer behaviors. These unprecedented changes call for a broader shift in marketing tactics and investments to successfully navigate the current transformed landscape.

Reshaping Wealth Tech
Before the Covid-19 inducted recession, the wealth tech sector was already experiencing a slowdown - both in the number of new startups and total capital raised. Now more than ever, investors and operators must be bold in re-inventing their Firm's long-term value proposition.

Age of Contactless Mobility
Cities are at a standstill, but they are bound to get moving again. Urban mobility will never be the same, and contactless payments will shape the new normal. Trends are shifting, preferences are being broken, and opportunities abound!

How to Thrive in the New Normal
Now that Business As Usual is unusual, leaders are forced to re-imagine business models and build ‘winning strategies’ - to not only survive the pandemic but also emerge as successful change-makers, shaping an altered business reality.
The Path to Decentralized Finance
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

An Agile Approach to Digitalizing Wholesale Banking
Credit has seen its fair share of ups and downs, from being the crux of financial services, to commoditization and mass distribution, to now being re-engineered. In the realm of Wholesale Credit, a revolution is underway.

Trends in Digitalization of Insurance
For some, Insurance might seem a monolithic industry, but for the ones keeping a close eye on it- Insurance is revamping itself faster than ever!
From days when underwriting a simple policy would take weeks and months, to now when it can be done in seconds with a simple ‘selfie’ - there seem to be no bounds in the future of this industry.

Customer Engagement Index
While firms have found tremendous success in using these loyalty metrics to successfully grow customer relationships, they are lagging indicators and provide little help in providing immediate insight into whether or not improvements and initiatives are moving the needle.

Strategic Sourcing of a “Difficult” Spend Category
Some clients have even deemed spend reduction in procurement categories like legal services, where recourses and expertise are concentrated within humans not technology, to be intractable. At Kepler Cannon, we continuously challenge these sorts of conventional wisdom.

Third Party Information Risk Mitigation
It is well known that one way to make better predictions about how your customers, distributors and suppliers will behave, is to augment your own data with that of third parties.

Driving Productivity Through Systems Selection
Procurement often involves multiple disparate stakeholders, systems and protocol. This complexity results in increased reliance on inefficient sourcing processes and only partially takes advantage of all the benefits available from supplier competition.

Putting IT Infra Consumers on a Diet
One question seldom asked is “how do I put my (IT infrastructure) customers on a diet?” The demand side is often assumed as a given, and there is with little assessment of (over-) consumption by applications.
Reducing Strategic Over-Dependence on IT Vendors
Over time, many firms realize that they have become so reliant on vendors/contractor for critical knowledge on key applications, that they have, in fact, ceded control of those applications to the vendors.

Are Blockchains Evolving Like Securities Exchanges?
Driven by data security concerns, a majority of financial institutions are now looking at so-called private or hybrid blockchains, rather than fully decentralized public blockchains (like the blockchain used for Bitcoin)

How Global Resourcing May Be Killing Your Company’s Efficiency
As global firms respond to the post-Great Recession regulatory and economic realities, efficiency of the back-office has become critical to ongoing success.

Third Party Vendor Risk – A Continuous Mitigation Strategy
The last thing any multinational organization wants to worry about are business and compliance risks introduced by third party vendors.

Everything You Wanted to Know About Blockchain (But Were Too Afraid to Ask)
As cryptocurrencies and their underlying ledger system gain momentum, many financial institutions are trying to determine how to best be part of this revolution. In particular, they want to know how best to update their existing IT architectures and operations to capitalize on this new technology.

Smart Blockchain Contracts: Are We Finally Going Paperless?
Smart contacts offer the potential to facilitate or fully automate processes that are heavily paper-based today, particularly long-winded, expensive legal processes.

Enabling Growth through Practice Management
In the world of financial advisory, growth strategies often focus squarely on the end client; after all, growth is achieved through new client acquisition or new asset acquisition from existing clients. While this logic is not incorrect, it fails to acknowledge the intricacies of third party distribution.

Reshaping the Indian Life Insurance Market
The Indian life insurance market is the fifth largest in the world. Although the per capita premium remains lower than in other emerging markets, the size and growth of India’s working class remains one of the largest globally, presenting enormous opportunity for life insurance companies to expand into and within the Indian market.

The Growing Asian Wealth Management Market: Capturing the Mass Affluent Opportunity
One of the largest and fastest growing wealth segments, the Asian mass affluent, is projected to hold $43.3 trillion in assets by 2020, yet only 20% of all wealth in Asia is tapped by the wealth management industry.

(Not) Selling Life Insurance in Asia
Amidst a boom in insurance business, Asian consumers remain largely underinsured.

Role Reversal: The Future of US Banks in the Online Lending Market
Following the financial crisis in 2008, Fintech startups gained a lot of prominence globally as consumers started to look for alternatives to traditional banking methods. These startups have penetrated every service area of consumer retail banking with the goal of dis-intermediating banks and becoming the new leaders of the financial services industry.

The Unbundling of Retail Banking
Not unlike a piece of software, retail banking can be portrayed as a stack comprised of 3 layers, where the complexity of each services can be abstracted into discrete segments and end products.

Binge-Worthy Digital Advice
While the trajectory of ‘digitization’ in financial services is encouraging, there is still significant demand from customers to expand and evolve their digital experience.