COST CHALLENGES WITH CLOUD ADOPTION
‘The proportion of IT spending shifting to cloud will accelerate post COVID-19 crisis, making up 14.2% of the total global enterprise IT spending market in 2024, up from 9.1% in 2020’ – Gartner
The adoption of cloud services among medium and large enterprises has grown exponentially in the last decade and it continues to be one of the fastest growing cost heads in IT department. Switching over to cloud services addresses many of shortcomings in the traditional on-premise model, such as the ability to ramp up and scale down volumes as per varying business requirements. According to a Gartner study, worldwide public cloud end-user spend was $260 Billion in 2020, and is projected to grow by 18% to $305 Billion by the end of 2021(1). However, cloud adoption comes with its own challenges: with increased adoption, an increasing amount of corporate money is pushed into cloud, and most businesses have yet to figure out an efficient way to track consumption and control cloud costs.
Traditional IT storage and computing spend used to be a capital expenditure with well defined process controls and budget allocation. Although these large purchase orders of equipment, space, software, etc., might not have been the most optimal investments, they provided enterprises with visibility and control through beforehand budgeting.
With the migration to cloud, the cost transformed into an operating expenditure with expenses being billed at the end of an accounting period. The autoscaling capabilities in cloud, pay-as-you-go pricing model, and the lack of understanding of pricing methods makes it difficult to track cloud usage in real-time. According to Forbes, 30-35% of the cloud spend is wasted(2) due reasons such as subscription duplications, uncontrolled expansion, underutilized instances, and other inefficiencies due to lack of monitoring. A typical large enterprise spends more than $6 Million in cloud in a year2; this means that more than $2 Million is wasted due to absence of visibility and monitoring of spends.
There are multiple additional challenges that lead to inflated cloud spend. Common cloud management obstacles that need to be addressed include:
– Lack of transparency: No defined process to breakdown and allocate overall cloud costs to individual projects and functions.
– Complex billing process: Invoices are highly complex and extensive due to all the plethora of cloud configurations created by various departments. A single invoice can span thousands of pages.
– Inefficient practices: Absence of a defined process to spot unused and unattached resources set up temporarily during model development cycle.
– Limited training: Engineers are not trained and incentivized to optimize servers based on computing, graphics, storage capacity and throughput analysis.
– Demand control: Many enterprises fail to take advantage of cheaper rates through upfront instance reservation based on disciplined demand forecasting, leading to increased use of spot instances. As of 2020, only half (~53%) of AWS users are reserving instances, this proportion being even smaller for Azure and Google Cloud1. By underinvesting in demand forecasting capabilities, companies are giving up a significant source of savings.
– Tiered pricing: Business leaders are not cognisant of tiered pricing available in certain cloud offerings such as Amazon S3 that could potentially provide significant volume-based discounts.
As businesses look to onboard more users to the cloud, lack of usage guardrails and resource visibility can exponentially increase cloud costs, offsetting potential savings from increased efficiency. As cloud expenditure becomes a primary part of the overall IT expense, having a well-thought-out cloud cost optimization strategy becomes critical.
FRAMEWORK TO MANAGE COSTS
Contrary to popular belief that cloud adoption lowers costs and increased efficiency, the key to unlocking savings lies in implementing controls. Unplanned and uncontrolled usage of cloud resources often leads to piling up of unused instances that do not add any value but still need to be paid for. In the medium term, these practices lead to a negative ROI from migrating to the cloud. For end-to-end management of cloud costs, Kepler Cannon has a proprietary framework (Exhibit 1) that has been implemented across several enterprises. Cloud costs are always a direct or an indirect function of quantity and price, the two fundamental levers of cost optimization.
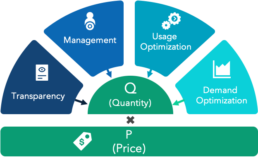
Exhibit 1: Cloud Cost Optimisation Framework
– Quantity: First step to managing costs is to reduce the quantity. With on-premise infrastructure, the usage costs or ‘quantity’ costs are usually limited to the electricity consumption by the hardware, hence leaving systems running overnight and other inefficiencies are common and bear no consequence, but with cloud infrastructure, vendors keep track of and charge for each second of usage. Hence, it becomes important to avoid such wastage and cut down consumption to necessary levels.
Quantity management can be carried out by enhancing visibility into usage and spend, setting up management guidelines, optimizing usage by removing inefficiencies and using predictive analytics to forecast demand for the next billing cycle.
– Price: Parallel to managing the quantity, enterprises can also look to optimize pricing. As intuitive as it sounds, this step, which can deliver significant savings, is often ignored by enterprises. Price management could be done at either a vendor level or individual product level. At an aggregate level, this practice includes selecting the right vendor based on needs, exploiting preferred status, negotiating volume-based and sustained use discount. Further savings can be attained at a product level through optimal pricing schemes and attention to tiered pricing methods, among others.
MANAGING QUANTITY
Several initiatives can be designed to optimize the volume of cloud resource consumption. Few of the schemes that worked exceedingly well in multiple institutions are described in this section.
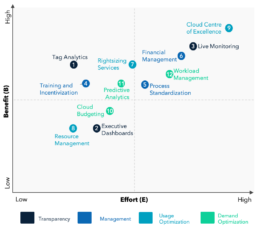
Exhibit 2: Cloud Cost Management Initiatives
EMBRACING DOMAIN CENTRICITY
Transparency
The first step towards cost optimization is to gain visibility into the key cost drivers and attribution to different services and resources. The problem of visibility into cloud spending arises because of its vast scale of use and aggregate, enterprise-level billing. Moreover, businesses using more than one cloud service provider or hybrid cloud models face even greater difficulties in obtaining a transparent spending view due to the lack of consolidated usage reports.
1. Tag Analytics:
Businesses should keep track of overall costs by tagging resources with project IDs, cost centers, etc. enabling breakdown of cloud costs across LoBs, and business functions (analytics, marketing, sales, services, etc.). Cost allocation reporting can be further enhanced with additional features such as instances (on-demand, spot, reserved), payment tenure, etc. Resource tagging would also help in reporting cloud usage at granular time intervals such as daily or hourly periods and performing heatmap analysis.
Post allocation and cost efficiency analyses are critical for understanding the value of every dollar spent on cloud services and assigning cloud costs to customer types and business initiatives to augment profitability and impact analysis.
2. Executive Dashboards:
Dashboards on expenditure across different services, use cases and changes over time can provide insights to leadership and help uncover recurring patterns, spikes, etc., and help predict future demand. Transparency also helps to highlight cost anomalies (spikes on weekends / holidays), seasonality, and perform root cause analysis. Moreover, cloud vendors have also launched visualization tools such as AWS cost explorer, usage report, Azure and GCP cost management, etc. to enhance cost transparency.
3. Live Monitoring:
As an advanced attribution capability, businesses can design real-time visualization tools for daily administrative staff to monitor utilization, track cloud resource inventories and send out automated alerts on spikes in resource counts as compared to pre-defined thresholds. This provides real time comparison of accrued costs against allocated budgets and escalation to concerned authority in case of anomalies.
Management
After gaining sufficient visibility into the spend, the next step for businesses is to set up a cloud resource management process encompassing robust budgeting, control measures, and design guardrails for users of cloud resources.
4. Training & Incentivization:
The root of most inefficiencies in cloud usage arises at the user level itself. Therefore, one of the most effective ways to cut down on costs is to train the engineering staff for efficient usage. Raising consciousness among employees on inefficiencies in cloud usage and corresponding financial impacts to the firm, and socializing best practices on proper utilization of resources, identification of idle instances and server optimization will provide long standing benefits for all enterprises. Moreover, businesses can incentivize their employees by designing recognition schemes for best performing teams on optimal resource usage over a sustained time period and raising awareness amongst employees by coaching through mistakes and inefficient practices.
5. Process Standardization:
Based on historical data, administration can set up resource usage standards, ownership hierarchy and escalation process at the start of new projects. For ongoing projects, monitoring of resource usage can create a standard frame of reference for benchmarking utilization. Businesses can also set up a monthly monitoring process to investigate running inefficiencies, underutilized resources, and evaluate different initiatives based on pre-defined metrics such as cost, speed and quality.
6. Financial Management:
To further enhance resource management, a dedicated, enterprise-level cloud management function can be set up to achieve financial success and business value realization in cloud. Administration can also create chargeback mechanisms such as an internal resource buying processes to keep track of running usage of cloud instances and accrued costs.
Usage Optimisation
Monitoring and optimizing usage is of utmost importance while using public cloud services. Each second of cloud consumption is billed by vendors and even slight mistakes and inefficiencies can have a bleeding effect on dollar bills. Cloud usage can be optimized through detecting inefficiencies, standardizing processes and consolidating services.
7. Rightsizing Services:
Data engineers should be incentivized to analyze computing services and optimize them to the most efficient size among the available combinations. Furthermore, they should ensure peak performance from resources through optimizing servers for memory, graphics, computing, throughput, etc. At an enterprise level, as cloud vendors release new services and features, firms should review existing architectural and resource usage patterns.
8. Resource Management:
Using DevOps, application developers do not have to manually turn off temporary instances after job completion, as automatic instance termination serves to reduce spurious resource consumption. Furthermore, any suboptimal utilization of compute instances can be quickly identified and avoided: instances with low utilization figures can be consolidated and used more optimally. Firms need to have provisions for centralized administration to identify and shut down unused or unattached resources at a predefined frequency across all departments.
9. Cloud Centre of Excellence:
Tying in with a financial management capability, a centralized financial operations team can monitor for potential wastages in resources and optimize consumption and look for possible rate optimization for specific services. Due to the presence of pricing tiers, lowered resource usage may not always be the best strategy. Hence, cloud CoEs can also perform periodic cost-benefit analysis to prioritize pricing tiers over optimization of resources in specific business functions.
Demand Optimization
Based on historical data, forecasting demand for next billing cycle can help in reserving the right amount of capacity and avail lower rates from cloud vendors. It can also help enterprises choose new features or products they need to add, and the required user counts.
10. Cloud Budgeting:
Developers can provide resource usage estimates based on prior experience and upcoming activities. Such forecasting of resource requirements across projects, business functions and strategic initiatives can help sanction funds accordingly. A proper budgeting exercise can allow businesses to leverage spot instances for applications that are fault-tolerant and can be processed in batches. Reserved instances can save money over on-demand capacity for multiple cloud products.
11. Predictive Analytics:
Companies need to invest in analytics capabilities to forecast demands and identify usage patterns, cyclicality, etc. Visualization of historical computing demands and heatmaps can illuminate development server usage patterns. Such insights can be leveraged to design protocols for data engineers such as mandatory closing of specific jobs at the end of the day or week and establishing start and stop times in scheduling instances to optimize on costs.
12. Workload Management:
As an advanced capability, the demand curve can be smoothened by using throttle, buffer, queue, or processing as a batch service. While dealing with large cloud usage, companies can invest in automatic provisions for resources to match workload demand through auto-scaling or closing out resources as needed.
MANAGING PRICE
With an increasing number of players offering cloud services, industry prices are becoming competitive. Vendors have introduced various pricing schemes to maximise their revenues. However, many customers still do not manage their costs. Cloud spend can be reduced by exploiting relationship discounts and optimal selection of pricing scheme for individual cloud services. These could be done at either the vendor level or individual product level.
Vendor Level Optimization
Economies of scale helps reduce rates; as such, enterprises should try to switch over to a single vendor to leverage volume-based discounts unless a multi-vendor strategy is needed to serve specific business needs. Aggregate accounting and reporting at an enterprise level can help ensure maximum discount on rates. Moreover, there should be incentives to drive up firm-wide usage of cloud services as opposed to on-prem, wherever possible to optimize overall IT spends.
To drive up customer loyalty and revenues, cloud vendors also provide users with sustained use discounts. These consist of cheaper rates with longer term contracts and higher discounts based on customer tenure. Enterprises should look to exploit such schemes to negotiate better rates and discounts upfront.
Product Level Optimization
Cloud computing vendors often offer multiple pricing models for their product offerings. These pricing tiers are generally based on resource demand, required back-end infrastructure, etc.
The optimal rate varies across enterprises and depends on the specific requirements and strategic importance. In-depth analysis and selection of the available options is required. For example, AWS’ EC2 is offered with four different pricing schemes(4).
– On-demand: Offers no upfront payment but high price for instances. It is best used for applications with unpredictable workloads.
– Spot instances: Prices are discounted compared to on-demand. It should be for applications with flexible start and end times.
– Reserved instances: Second cheapest option optimally used for applications with steady-state usage.
– Savings plan: Cheapest rates in exchange for commitment to consistent usage for a 1/3-year term.
Similarly, other players like GCP and Microsoft Azure also offer various pricing tiers for their products like for Azure Virtual Machines. Detailed analysis of available options at an individual product level will help determine the most optimal pricing scheme and help cut down costs.
IN CONCLUSION…
As enterprises complete their cloud migration journey, their IT infrastructure costs will also transition from a capital expenditure model with strong budget controls to an operating expenditure model, where expenses are visible only after accrual. The auto-scaling feature of public clouds and pay-per-use pricing model, makes it less of a mandate for businesses to track cloud resource usage. Lack of visibility and unnecessary usage often shoots up cloud costs, potentially offsetting benefits from increased efficiency. As cloud expenses become a more integral part of the overall P&L, business leaders need to come up with a holistic cloud cost optimization plan to ensure competitiveness.
Organizations need to design separate initiatives and deploy an exhaustive set of coordinated schemes under the umbrella of a well-structured, end-to-end strategy as they look to regain control of the IT infrastructure expenses. A thorough assessment of the business requirements and resource criticality of different functions is recommended to tailor different solutions for individual business considerations. Partnerships with experts in this field can significantly help with innovative ideas, identifying inefficiencies through an outside-in view, and selecting optimal pricing schemes to unlock maximum savings.
References:
- Gartner, Nov 2020
- Forbes, Feb 2018
- Flexera, State of the cloud report, 2020
- AWS Website
Read More

From Interface to Intelligence
The next frontier of digital commerce is not better checkout, but better coordination. This whitepaper examines how agentic AI is transforming fragmented transactions into intelligent, autonomous experiences - and what businesses must do to stay ahead.


Banking on You – Personalization in Financial Services
Capturing and sustaining attention is key to building customer loyalty, driving sales, and standing out in a competitive landscape. In this attention economy, what really helps business maintain relevance is to personalize the interactions for their needs, context and preferences.

The Open Book on Compliance – US Open Banking Regulations Decoded
The CFPB’s new Open Banking regulations will impact how financial service providers can access and monetize consumer data, while also influencing future practices around security, consent, and data sharing.

Mixed Reality
As these technologies become more accessible to the wider public, AR and VR are expected to grow into a $125 billion market by 2025.

Money Games
The use of gamification has proliferated across all industries, with retail, entertainment and education leading the charge. Apps like Duo Lingo, Kahoot, Fitbit, Starbucks etc., are all some of the most prevalent examples.

Monetizing Data Analytics
For several years, it has been said that “data is the new oil” and arguably, the most valuable strategic asset for a business. Whilst getting value out of data might be less straight-forward, it is true that data needs to be refined to make it valuable.

From Cards to Chains – Payments in the Blockchain Era
To remain competitive in the evolving financial landscape, card networks are uniquely positioned to bridge this gap between traditional payments and new blockchain networks as transaction facilitators, leveraging their global reach to make transactions on their networks quicker, cheaper, and more secure.

A Borderless World
Significant shifts are underway in the cross-border payments sector, across the demand-side and supply-side. Consumer expectations from domestic payments (instant, fully traceable, risk-free, etc.) are being applied to the more complex cross-border space. Businesses that capitalize on these shifts stand to shape the future of the industry.

Cracking the FedNow Code
Real-time payments are increasingly recognized as a critical component of modern financial systems, offering speed and convenience in an interconnected digital world. As we venture into the future, the recent launch of the Federal Reserve's instant payment service, FedNow, stands at the forefront of a payment revolution in the US.

Future-Proofing Healthcare Delivery
The right telehealth platform is critical to meeting patient expectations and providing the best possible provider, patient and administrator experience. Today patients are demanding more control over their healthcare and want to access care from anywhere.

The GenZ Wave
Gen Z is not merely a younger version of millennials; they are poised to disrupt all aspects of the economy. Companies must therefore adapt in time to cater to the preferences and expectations.

Gaming and Financial Services
As younger generations start to play for competition and skill development, there is a rise in payment flows, volumes, and subsequent opportunities arising out of the same. Financial institutions are not only presented with the opportunity to monetize on gamers but also target younger Gen Z and Millennial consumers to upsell and cross-sell their existing products.

Maximizing Value from Value Added Resellers
The role of Value Added Resellers (VARs) is transforming from basic reselling to strategic technology partnerships that offer comprehensive IT solutions. To maximize the value of these evolving relationships, firms must bring transparency to pricing, agreements, and the scope of work.

Latent Growth in LatAm Credit Cards
The payments industry has been experiencing explosive growth across Latin America over the past few years: cash usage has decreased ~20% as consumers pivoted towards payment products that are well integrated into the financial ecosystem.

Navigating the Buy Now Pay Later Era
The rising aspirations of consumers combined with the limited access to, and opaque nature of traditional financing solutions, has given rise to innovative products for underserved segments. BNPL is one such solution that offers short-term financing to users with the ability to pay in definite installments with low to no interest rates.

Modernizing B2B Client Delivery
Leading B2B firms are very well aware that their client delivery experience needs to have the same levels of service, responsiveness, transactional ease as any digital consumer experience. Majority (72%) of B2B buyers expect a similar experience on a B2B site as they get on a consumer website (1).

Winning in Mature Markets
Competition is an important facet of business world, and the process of seeking growth is a continuous one. One should never stop trying to win new customers or retain existing ones. After all, competitors are always trying to win your customers over, especially in mature markets.

Putting Customers At The Core of Your Business
Digital Transformation is about developing new capabilities and leveraging new channels to design and deliver a better client experience.

Realizing the Reality of Real Time Payments
Real time payment (RTP) transactions are likely to exceed 300B by 2023, growing at 40% per year worldwide. Financial Institutions need to quickly find their own space in this ecosystem. They must redefine their value proposition and rethink their business models around this phenomenon.

Client Loyalty 2.0
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

The Tale of Two Countries – Insurance
The pandemic has created unprecedented challenges for the insurance industry. Experiences of the world’s biggest economies (U.S. & China) offer valuable lessons as to where the industry can improve and change in order to better handle similar events in future and build sustainable risk management systems.

Path to Innovation
Innovation has been in vogue for over a decade but the need to be innovative has never been felt as strongly as today. As businesses are learning to thrive under the lasting effects of the pandemic, they need to reinvent products, services and customer experiences to satiate emerging patterns of demand. To truly capitalize on the opportunity, business leaders need to look beyond internal capabilities and embrace a networked model of innovation to drive positive impact.

Reimagining Marketing
The COVID-19 pandemic has re-shaped the landscape for marketers. They are not only forced to cut budgets to save costs, but also face the challenge of keeping up with new emerging customer behaviors. These unprecedented changes call for a broader shift in marketing tactics and investments to successfully navigate the current transformed landscape.

Age of Contactless Mobility
Cities are at a standstill, but they are bound to get moving again. Urban mobility will never be the same, and contactless payments will shape the new normal. Trends are shifting, preferences are being broken, and opportunities abound!

The Path to Decentralized Finance
We are on the cusp of a revolution within financial services that will have far-reaching ramifications for the +1 billion unbanked, current models of financial intermediation across entities and borders, and ultimately the very nature of how end-consumers understand financial health. As this understanding held by customers evolves, so too must the operations, services, and visions of providers.

An Agile Approach to Digitalizing Wholesale Banking
Credit has seen its fair share of ups and downs, from being the crux of financial services, to commoditization and mass distribution, to now being re-engineered. In the realm of Wholesale Credit, a revolution is underway.

Driving Productivity Through Systems Selection
Procurement often involves multiple disparate stakeholders, systems and protocol. This complexity results in increased reliance on inefficient sourcing processes and only partially takes advantage of all the benefits available from supplier competition.

Putting IT Infra Consumers on a Diet
One question seldom asked is “how do I put my (IT infrastructure) customers on a diet?” The demand side is often assumed as a given, and there is with little assessment of (over-) consumption by applications.

Smart Blockchain Contracts: Are We Finally Going Paperless?
Smart contacts offer the potential to facilitate or fully automate processes that are heavily paper-based today, particularly long-winded, expensive legal processes.

The Unbundling of Retail Banking
Not unlike a piece of software, retail banking can be portrayed as a stack comprised of 3 layers, where the complexity of each services can be abstracted into discrete segments and end products.

Binge-Worthy Digital Advice
While the trajectory of ‘digitization’ in financial services is encouraging, there is still significant demand from customers to expand and evolve their digital experience.