Addressing Bad Data in Healthcare
In healthcare, accurate data is not just a luxury—it is a necessity, essential for operational success and improved patient outcomes. For clinics, providers and payers, the integrity of both provider and member/patient data underpins critical business areas such as patient care coordination, claims adjudication, and fraud detection (Exhibit 1). However, despite its significance, many organizations remain focused on transformation and modernization, often overlooking the fundamental issue of data quality. In fact, only 20% of healthcare organizations fully trust their data, and just 46% prioritize data quality in their strategic investments.
This oversight not only introduces inefficiencies and risks but also directly threatens patient safety and undermines organizational performance. While modern tools have the potential to deliver efficiency, they are not a cure-all for the deeper issues caused by poor data quality. True transformation requires a commitment to data integrity. Furthermore, the benefits of AI can only be realized when the underlying data is trustworthy and accurate.
Poor data quality also erodes trust in the relationships between
providers, payers, and patients. Alarmingly, 30% of consumers report having skipped care due to inaccurate provider information, further straining the provider-patient relationship and the trust in the health system.
In this paper, we explore the far-reaching consequences of poor data quality and emphasize addressing the underlying quality issues. By focusing on both aspects, organizations can unlock the full potential of their technological investments.
Exhibit 1. Data’s Pervasive Influence
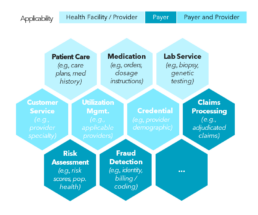
Complexity of Health Data
1. SCATTERED DATA
Data in healthcare organizations often exists in multiple locations. This further gets complicated by legacy systems. These outdated systems necessitate supplementary solutions to maintain their functionality, which further fragments the data. This fragmentation disrupts the information flow, increasing the risk of inconsistencies and breakage. Additionally, the data flow is multidirectional and involves input from various teams at each stage. For instance, the population health team plays a role not only during the prior authorization for payers but also during reconciliation in claims adjudication.
2. NO UNIFORM PATTERN
Practice of documenting clinical facts and findings on paper has
ingrained a habit within the industry of capturing data in ways that prioritize convenience for individual health facilities, often with little consideration for how this data might later be aggregated and analyzed. A similar challenge exists on the payer side, where medical claims are submitted in both electronic and paper formats. Even among electronic submissions, there is a lack of consistency—some claims require bill / other types of attachments (e.g., HL7s), while others do not. This variability complicates the process of data standardization.
3. INCONSISTENT DEFINITIONS & WAYS OF WORKING
Often clinicians define different cohorts of patients in varying ways, leading to a lack of consensus on treatment approaches or cohort definitions. This inconsistency is further complicated by regulatory pressures and requirements on payer side. For instance, in Arizona, Medicaid mandates post-adjudicated claim submissions to regulators, a requirement that differs significantly from those in other state programs. These variations create additional challenges in achieving uniformity and consistency in patient care and data management across regions and health systems.
4. AMPLIFYING DATA VOLUME
The number of data variables and supported formats makes it
challenging to handle data all at once (e.g., HL7, FHIR). Moreover, the volume of data is evolving. For instance, provider data, especially demographic data, changes continually (~2% changes each month). Other data attributes, such as affiliations, status and sanctions, also change frequently.
5. EVER-CHANGING REGULATIONS
Regulatory requirements are continually increasing and evolving. The Centers for Medicare & Medicaid Services (CMS) now require detailed quality reports on metrics such as readmission rates. Similarly, healthcare reform requires more transparent quality and pricing information for the public. The shift toward value-based purchasing will further intensify the reporting demands.
Data is at the Heart
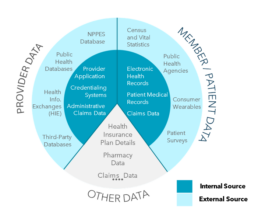
Before addressing quality issues, it is crucial to first understand the fundamental components of healthcare data. What exactly needs to be cleaned? At the core are provider and patient / member data — two essential types that are indispensable to the daily operations. Accurate provider data is essential not only for verifying that healthcare professionals are qualified and capable of delivering care, but also for ensuring they receive the correct payments for claims filed. Similarly, reliable patient / member data is crucial for enabling informed decisions about treatment options and care pathways. The interaction between these two data types is vital, as their precision and consistency have a direct and significant impact on the effectiveness of operations.
They are inherently complex and diverse, encompassing various types that span both health facilities and payers. This data landscape is further complicated by a lack of standardization, differing underlying data sources, varying definitions, and an ever-growing volume.
(SELECTED) PROVIDER DATA:
✓ Personal Information: Names, addresses, contact details, National Provider Identifier (NPI) numbers
✓ Professional Attributes: Licensure, specialties, education, affiliations with healthcare facilities (e.g., hospitals, clinics)
✓ Operational Information: Accepted insurance networks,
credentialing details, language proficiencies
(SELECTED) MEMBER/PATIENT DATA:
✓ Demographic Information: Age, gender, ethnicity, socioeconomic status
✓ Health History: Medical conditions, treatment history, allergies, medications
✓ Insurance Details: Coverage information, policy numbers, eligibility
Both provider and member / patient data come into the ecosystem from various sources, each of which needs to be considered for data quality (Exhibit 2).
Exhibit 2. Sources of Healthcare Data
Why Quality Matters
It is estimated that dirty data costs the U.S. healthcare industry ~$300B annually and the impact is multifaceted:
1. OVERUTILIZED LABOR: Inaccurate data leads to redundant tasks and rework, forcing healthcare professionals to devote excessive time to administrative duties instead of patient care. It typically takes 20-40 minutes per file to rectify such errors, increasing the claims processing FTE cost by an additional 20-40%. This includes the time spent maintaining accurate records in EMRs, verifying duplicates, responding to regulatory changes, and correcting errors in the data.
2. INCREASED CLAIMS DENIAL: Hospitals incur an average loss of $2.5M annually due to denied claims resulting from inaccurate information. Similarly, out of the 30% of claims that fall out of the auto-adjudication process, 25% of them are attributed to provider data quality issues. This results in an added $1M for a payer with 1M claims.
3. GRIEVANCES AND APPEAL: Increased denial rates and manual adjudication results in an increased volume of grievances and appeals between the patients, provider and payer. Addressing these issues further drives up the costs. For example, inaccurate directories lead to a higher rate of returned mail, with 9-14% of all mail sent to providers being returned with each mail costing ~10% of the claims processing cost. Factoring in additional expenses related to voids, reissues,
adjustments, and outreach calls; the total costs escalate dramatically.
Exhibit 3. Costs of Poor Healthcare Data Quality
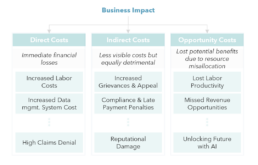
4. COMPLIANCE AND PENALTIES: Inaccurate data can lead to
substantial penalties for non-compliance. The Centers for Medicare & Medicaid Services (CMS) reported improper payments in the Medicare Fee-for-Service program totaling ~$28B. Additionally, violations of HIPAA can cost healthcare facilities up to $1.5M per violation per year and may result in reduced reimbursements.
5. REPUTATIONAL DAMAGE: Organizations risk eroding trust and satisfaction, which can lead to provider defections and member churn. ~88% of healthcare consumers verify the accuracy of provider information before scheduling a consultation. Inaccurate data can harm a brand’s reputation, accreditation, and market share, especially in public health programs where member allocation depends on bids.
6. LOST PRODUCTIVITY: Employees often divert their time from strategic initiatives to managing the fallout from data inaccuracies. For every 10 physicians providing care, seven additional people are needed for billing support, resulting in inflated costs.
7. MISSED REVENUE: Organizations may fail to fully capture income due to billing errors or submitting claims with inaccurate data, ultimately impacting their financial performance. For instance, a 10% improvement in data accessibility could generate over $65M in additional net income for a typical large healthcare organization.
8. SUB-OPTIMAL AI: The healthcare AI market is projected to grow at ~39%, reaching $187.7B by 2030. AI promises to enhance diagnosis, improve treatment outcomes by 30-40%, and significantly reduce costs. However, AI systems require high-quality, accurate data to function effectively.
No One-Size-Fits-All
Relying solely on technological or data aggregation solutions such as data warehouses, may streamline processes but often only addresses symptoms rather than the root causes of data issues. A comprehensive approach requires a thorough review of the entire data lifecycle.
Kepler Cannon has developed a framework for such an in-depth
diagnostic (Exhibit 4). There is no universal solution for addressing data quality issues, as root causes can vary significantly. By evaluating the entire lifecycle, organizations can pinpoint areas for improvement and prioritize actions to enhance data quality from sourcing through to final reporting.
In the following sections, we outline the steps necessary for a thorough data quality review. While each organization has different maturity levels and root causes, the review process remains consistent.
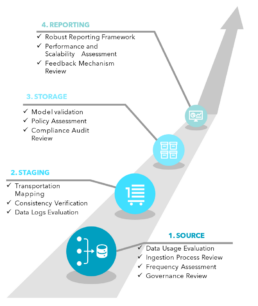
Exhibit 4. Kepler’s Root Cause Framework

Troubleshooting Across the Lifecycle
1. THE SOURCE
Ensuring data quality at its source requires a comprehensive evaluation of how and where the data is being used. This assessment should determine whether the current use of the data is optimal and identify any redundancies. Additionally, it’s important to assess the timing and process of data ingestion into the ecosystem, including the specific fields utilized, their relevance, and the overall quality of the data. The frequency of data provision should also be evaluated. Reviewing permissions and governance frameworks is crucial for maintaining effective data management and upholding data quality standards across the organization.
2. STAGING
The next step involves a thorough review of the data transportation processes. It’s essential to understand how data is transferred, the paths it takes, and the formats used, such as HL7 for claims. Ensuring that data in the staging environment consistently matches the original source is critical. Additionally, evaluating audit trails and data logs is necessary to detect any issues that might arise during transit, even if the source data is initially clean. Regularly reviewing data storage policies and keeping documentation up-to-date will help ensure these processes remain aligned with business needs.
3. STORAGE
Organizations should validate data models to ensure alignment with business requirements. Additionally, a thorough assessment of policies—including redundancy, backup, recovery protocols, and archival practices— can ensure compliance with retention requirements.
In healthcare, meeting compliance standards is particularly arduous due to varying policies across state lines. Therefore, reviewing compliance audits is necessary to adhere to HIPAA security mandates.
4. REPORTING
Organizations should ensure that data visualization tools and reporting frameworks accurately reflect the underlying data and align with business needs. Assessing the performance and scalability of reporting systems to manage large data volumes efficiently is crucial. Developing standardized reporting templates and processes helps maintain consistency, reliability, and compliance. Furthermore, reviewing feedback mechanisms to identify and address any issues is key to fostering continuous improvement and enhancing the overall effectiveness of the reporting system.
Exhibit 5. Approach to Troubleshooting Data
Unlock the Power Today
Data inaccuracies can lead to significant consequences, including patient / provider dissatisfaction, financial risks, penalties, increased call center traffic, lost revenue from risk adjustments, and overpayments. Additionally, poor data quality prevents organizations from fully leveraging AI.
This paper highlights just a fraction. Many hidden problems may go unnoticed, such as delayed treatments, rising costs, interoperability challenges, and other factors that ultimately compromise patient care.
These issues often arise from data accuracy problems, worsened by outdated technology and manual processes. While upgrading
technology is essential, equal emphasis must be placed on ensuring data integrity. Relying on advanced technology without addressing data issues will fail to deliver true value.
Managing data requires a tailored approach. Kepler Cannon’s proven frameworks allow for comprehensive, standardized assessments of data maturity across the entire lifecycle. This enables us to identify, prioritize, and resolve data leakages with customized solutions designed to meet each organization’s unique needs.